



Philo-S

Speech to Text (STT)

Learning voice data through deep learning-based acoustic models and converting it into textual information that advances speech recognition, speaker classification, and voice quality through RNN- based speaker vector generation.

Real-time voice recognition API service

Speaker separation analysis and noise cancellation technology through speaker voice filtering

Speech synthesis though text information
Features
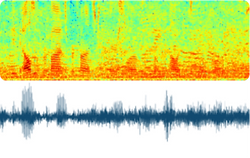
Speech with Noise
Noise elimination
by applying voice filtering
Speech recognition & separation + Quality enhancement

Use Case
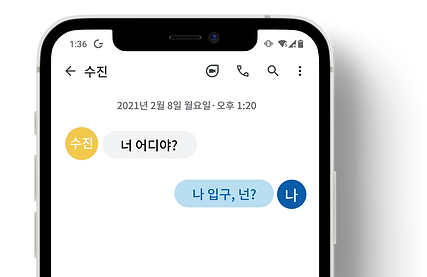
Realtime call transcripts to text
-
Recognizes the voice of each speaker separately and records the call as a text document
-
Possible integration with video call platforms
AI Speaker
-
Improved Speech recognition ratio
-
Collaboration with leading AI speaker manufacturers
-
STT for AI Speaker's NPL process
Online Classes
-
Recognize instructor's voice and generates handwritten notes automatically
-
Natural communication & feedback environment (Q&A)
Video Conferencing
-
Enhancement of voice quality by eliminating noise for each speaker
-
Automatically generates meeting minutes by each speaker through feature extraction and separation
Automated Subtitle Generator
-
Generates subtitles automatically by extracting audios directly from movies or audio files
-
Automated lyrics generation
Telemedicine
-
Q&A between doctors & patients
-
Possible integration with video call platforms
7 Speech Synthesis
-
Reads text information in a selected voice
-
AI professional announcer’s voice function